What is Kereva-Scanner?
Kereva-Scanner is an open-source static analysis tool that scans LLM workflows to identify security and performance vulnerabilities. Unlike behavioral testing ("evals") which can only catch issues in the specific scenarios you test, Kereva-Scanner examines code structure directly to find root causes of problems before they manifest in production. It analyzes your Python files and Jupyter notebooks without executing them, looking for issues across three main categories:
-
Prompt issues: Problems with how prompts are constructed, including unsafe handling of XML tags, subjective terms, long lists, and inefficient caching. These often lead to inflated API costs or inconsistent outputs.
-
Chain issues: Vulnerabilities in data flow, particularly unsanitized user input that could enable prompt injection attacks. These security holes can be particularly dangerous in production applications.
-
Output issues: Risks related to output handling, including unsafe execution and structured output validation failures that can break your application logic.
The OpenAI Cookbook
If you've worked with OpenAI's API, you've likely seen the OpenAI Cookbook at some point. It's a collection of example code snippets and notebooks demonstrating how to use OpenAI's APIs. From basic chat completions to complex RAG implementations, the Cookbook serves as a learning resource for developers building applications with GPT and other OpenAI models.
Important disclaimer: The Cookbook contains educational examples, not production code. These examples are intentionally simplified to demonstrate concepts clearly. Finding issues in these examples doesn't reflect poorly on the Cookbook's quality - it's expected in educational code that omits production safeguards for clarity. Our goal is to learn from these patterns, not criticize the resource.
Scanning the Cookbook: A Learning Exercise
Last week, our team decided to run Kereva-Scanner against the OpenAI Cookbook repository to demonstrate the scanner's capabilities and identify common patterns that might lead to issues in LLM applications.
What We Found
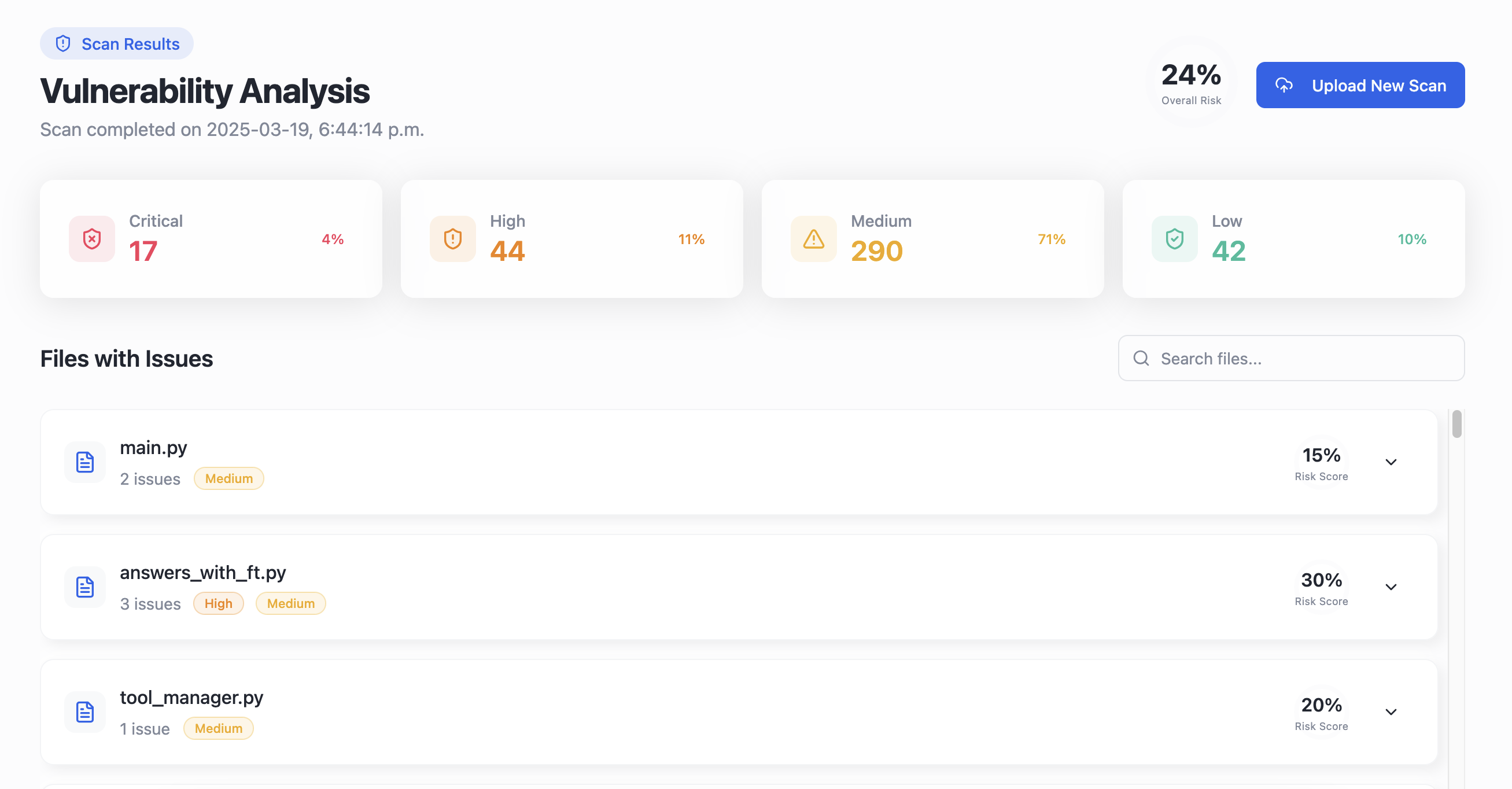
The scan identified 411 potential issues across the codebase. Here's the breakdown by severity:
- Critical: 17
- High: 44
- Medium: 290
- Low: 42
The most common issues were:
-
Prompt XML tag issues (114)
User inputs aren't properly enclosed in XML tags, which can reduce prompt injection protection. For example, instead of using:<user_input>{input}</user_input>many examples directly interpolate user input into the prompt. This creates risk of prompt injection attacks where users might insert text that manipulates the model into ignoring previous instructions.
-
Structured output issues (68)
Missing field constraints, descriptions, or defaults in structured output definitions. When using techniques like function calling or JSON mode, many examples lacked comprehensive schema definitions or validation, making outputs less reliable. -
Missing system prompts (83)
Many examples don't include explicit system prompts to constrain model behavior. System prompts are essential for establishing guardrails and consistent behavior, especially in production applications. -
Chain unsafe input (44)
User input flows to LLM calls and back to output without proper sanitization. This creates potential security vulnerabilities and data leakage risks, especially in multi-user applications. -
Subjective terms (37)
Prompts contain undefined subjective terms like "good" or "best" without clear criteria. Terms like these create ambiguity that can lead to inconsistent model outputs, especially as models evolve over time.
Key Takeaways
After reviewing the results, our team identified several patterns that developers should address when putting LLMs into production. Interestingly, many of these align with best practices we've learned the hard way through our own production deployments.
1. Input sanitization
Always validate and sanitize user inputs before sending to LLMs. This is the first line of defense against prompt injection attacks. Consider using libraries like LangChain's prompt templates or implementing your own sanitization logic that escapes special characters and delimits user input clearly.
2. Structured prompting
Use XML tags or other structured formats to clearly separate user input from instructions. This creates a stronger boundary between your system instructions and potentially malicious user inputs.